요즘 가짜뉴스, 통계조작에 대해서 인터넷 여러 커뮤니티에서 자주 언급됩니다. 드루킹 사건처럼 국민의 눈과 귀를 가리는 여론조작으로부터 대통령 지지율이 실화냐는 이야기까지 다양하게 나오고 있습니다. 제가 말씀드리고 싶은 것은 인터넷 댓글이 여론이라고 할 수 없으니 항상 사실관계 확인을 잘 하셔야 잘못 판단하는 일이 없게 된다는 것입니다. 사실관계에 대해서 잘못 판단하여 뒤따라오는 결과는 자신의 책임이며 또한 이 사화의 수준을 보여주는 일이 되는 것입니다.
이 글은 통계에 대한 명확한 이해와, 어떠한 통계의 해석이 타당한지 아니면 (편견 등에 의해) 기울어져 있는지를 여부를 진단하는 기초 지식을 확인하는 차원에서 썼습니다.
다른 학문도 마찬가지이지만 통계라는 학문도 서양에서 건너왔습니다. 그리고 그들도 역사적으로 수많은 통계오류(집계오류)와 잘못된 결론에 도달한 경험을 수많이 겪고, 그 원인분석을 하여 체계화 한 것입니다.
1. 실험 vs. 조사
통계적으로 실험과 조사는 다릅니다. 실험이라는 것은 어떠한 두 집단을 정해서 한 집단에게는 어떤 처방을 하고, 한 집단에게는 처방 자체를 하지 않는 식으로 처음부터 실험대상과 방법을 정한 후에 조사하는 것입니다. 신약을 개발했을 때, 이 약이 정말로 효능이 있는지 없는지, 있다면 어느정도 인지를 알아보는 등에 쓰이는 방법입니다.
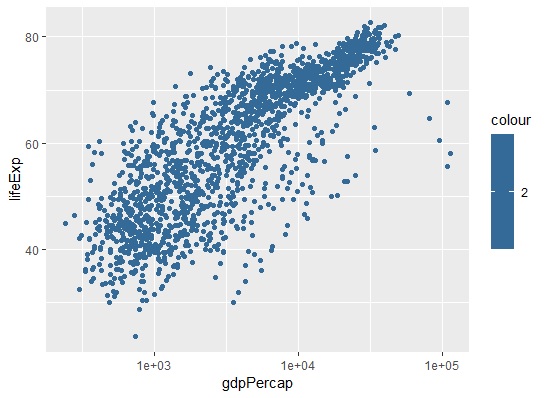
그에 반해서 조사는 말 그대로 조사입니다. 대통령 지지율 등의 여론 “조사”, 키와 몸무게의 관계등은 조사에 들어갑니다. 조사에서는 “키와 몸무게 사이에 관계가 있다”는 정도로 이야기 해야 합니다.
<<1인당 GDP와 예상수명>>
2. 표본 추출 방법
우리가 정확한 통계를 잡으려면 전수조사를 해야 한다고 합니다만, 전수조사는 시간상, 그리고 비용상 불가능할 때가 많고, 어떠한 경우는 전수조사 자체가 불가능한 경우도 있습니다.
예를 들어 두산 베어스와 한화 이글스의 승부에 대한 여론조사를 하는 있어서 전 국민을 상대로 전수검사를 한다면, 전수검사가 끝나기도 전에 경기가 끝나버리게 됩니다. 이렇게 되면 전수검사를 한 이유가 없게 되지요. 전수조사 대신 표본조사를 하는 것은 꼭 게으르거나 돈이 없어서만은 아닙니다.
결국 대부분의 경우에는 표본조사에 의존할 수 밖에 없고, 따라서 이 표본조사는 오차를 포함한다고 가정했기 때문에 5%등의 유의 수준(Significant Level)로 결론을 내게 됩니다.
결론을 내기 위해서는 몇 개의 샘플이 필요한가 하는 것은 통계의 정확도(오차)와 관련이 있습니다. 조그마한 차이가 되더라도 샘플이 상당히 많으면 “이 둘은 차이가 있다.”고 말할 수 있고, 비교적 큰 차이가 나더라도 샘플이 적으면 “이 둘은 차이가 있다고 말할 수 없다.”라는 결론을 내리게 됩니다. 예를 들어 국민을 상대로 표본조사를 하는데 4명 조사해 놓고 그 중에 3명이 대통령을 지지한다고 해서 대통령 지지율이 75%라고 발표한다면, 수 많은 사람들이 “그걸 통계라고 내고 있냐!”하고 화를 낼 것입니다.
그런데 이러한 수치상의 문제보다는 어떻게 표본을 추출하는가 하는 방법이 더 중요합니다. 표본이 전체를 대표하는 값이 되기 위해서는 무작위 샘플링 등을 해야 하는데, 이것도 몇 가지 문제점을 안고 있습니다. 예를 들어 20대, 30대, 40대, 50대 등등으로 대통령 지지율에 대해서 조사를 한다면, 이들의 숫자를 어떻게 나누는가 하는 문제가 있습니다. 연령별 차등을 두지 말고 통합해서 무작위 표본수를 많이(3000~10000)하는 것이 가장 좋다고 생각하지만, 여력이 없을 때에는 연령별로 숫자를 정해놓고 하는 것도 한가지 방법이 됩니다. 그러면 어떻게 연령대별 표본 숫자를 정하는가 라는 문제를 생각했을 때, 한국의 연령별 인구수로 나누는 것이 좋다고 생각됩니다. 또한 남/여, 지역별 샘플링을 하는 것도 인구 비례로 하는 것이 적절하다고 생각됩니다. 그렇지 않다면 뭉뚱그려 많이 조사한 다음 나누는 것이 낫습니다. 여론조사를 어떻게 조작할 수 있는지 하나의 힌트를 드렸습니다. 편중된(Biased) 조사는 편중된 결과를 도출합니다.
3. 인과 관계
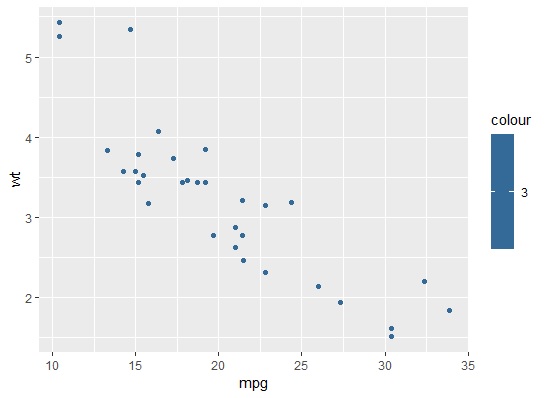
쉽게 예를 들어보겠습니다. 다음 그림에서 보면 무거운 차는 연비가 작고, 연비가 큰 차는 가볍습니다. 그렇다면 무게가 무거워서 연비가 나쁜지요. 아니면 연비가 나빠서 무게가 무거운지요. 이런 경우에 상식적으로 생각하면 알 수 있지요. 무게가 무거우면 더 많은 에너지를 필요로 하기 때문에 연비가 나쁜 것이지요.
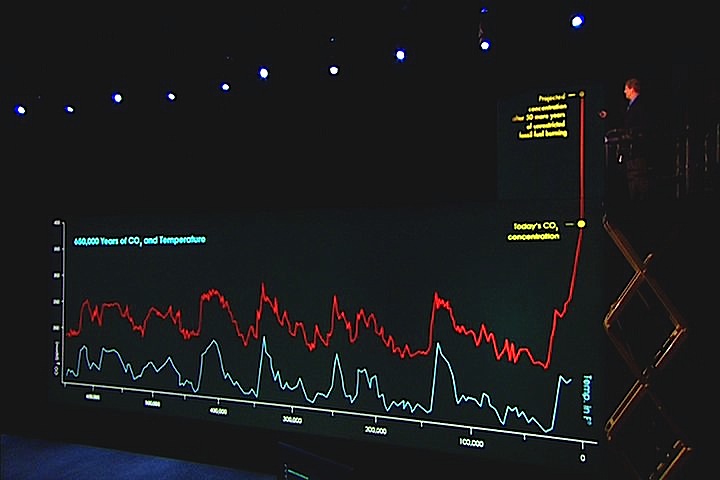
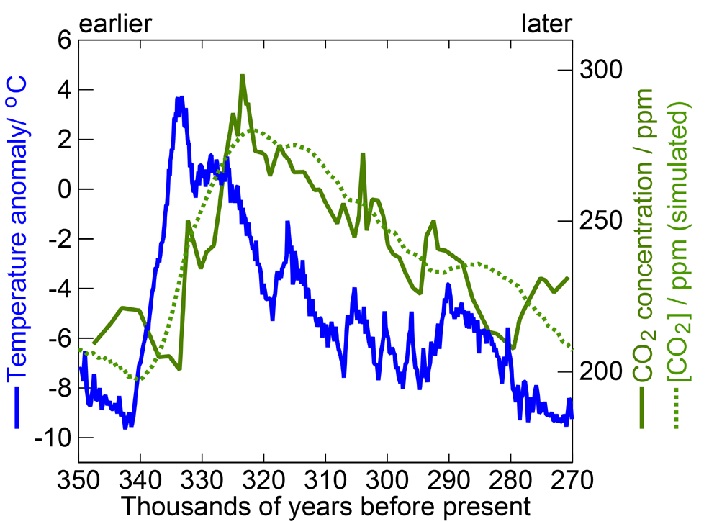
다음의 그래프는 유명한 앨 고어의 “불편한 진실”에서 나오는 그래프입니다. 여기서 는 이산화탄소의 양이 급격하게 늘고 있고 또한 지구의 온도도 올라가는 그래프를 볼 수 있습니다. 앨 고어는 “이산화탄소의 양이 많아지면 지구의 온도가 올라가기 때문에 이산화탄소의 양을 줄여야 한다”는 결론을 내리고 있습니다. 과연 그럴까요?
그림을 확대해 보겠습니다. 자세히 보면 온도가 먼저 올라가고 이산화 탄소가 따라서 올라가는 것을 볼 수 있습니다. 그렇다면 이산화탄소가 많아져서 온도가 올라가는 것이 아니라 온도가 올라가니까 이산화탄소가 많아지는 것 아닐까요? 원인과 결과를 해석함에 있어서 두 성분간의 움직임이 시간차가 있다면 무엇이 원인이고 무엇이 결과인지를 알아내는 힌트가 됩니다.
그래서 혹자는 앨 고어가 의도적으로 거짓말 했다고 하지요. 온도와 CO2의 원인에 대하여 과학자들은
태양의 영향에 의한 것이 주가 된다는 결론을 내고 있습니다. 온실가스의 93% 이상이 수증기이고 이산화탄소는 0.04%밖에 안되는데 왜 이산화탄소가 지구온난화의 원인이라고 묻는 물음에 앨 고어는 답변을 하지 못합니다.
4. Simpson’s Paradox
통계에서 심슨의 역설이라고 하는 것은, 통계를 냈지만, 중요한 변수를 감안하지 않고 통계를 냈을 때 엉뚱한 결론에 이르게 되는 경우를 말합니다. 다음의 그림을 보면 파스타를 많이 먹으면 비만지수(BMI)가 늘어난다는 하고 있습니다.
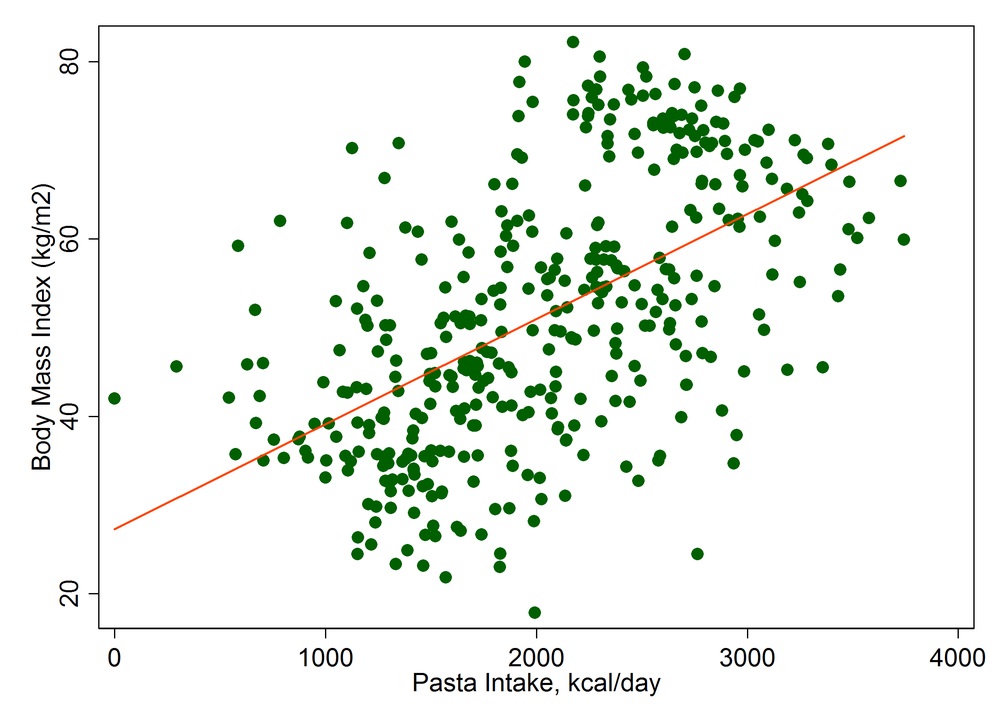
진짜 그럴까요? 여기서 하나의 항목을 더 고려하여 그래프를 색으로 구분해 보지요… 즉 사람들의 몸무게를 고려하여 4개의 군으로 묶었습니다.
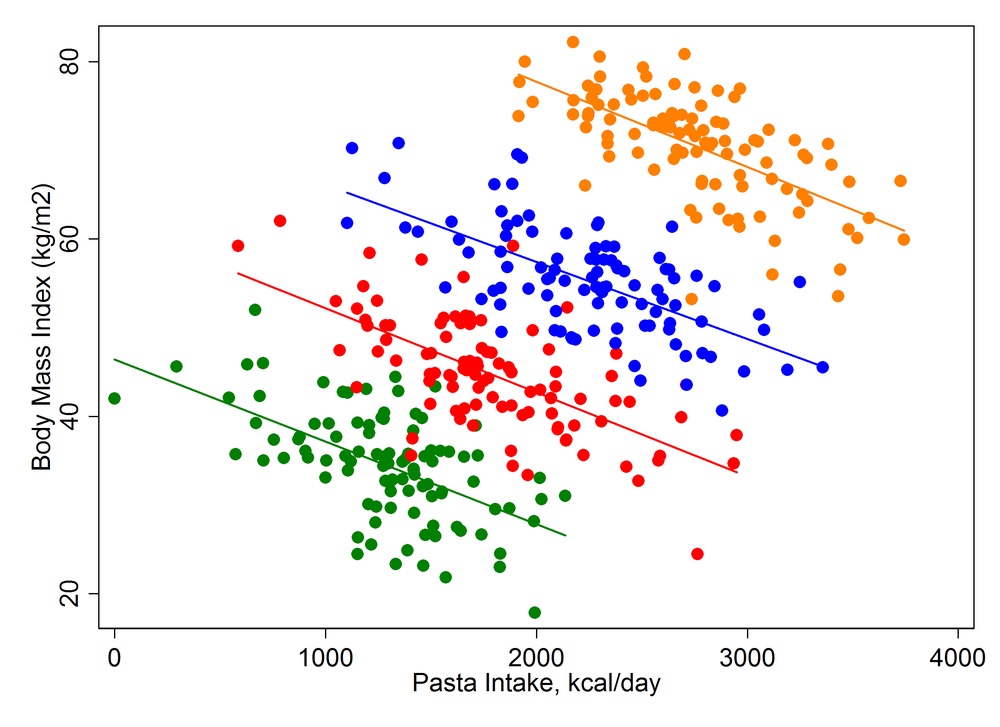
처음에 낸 “파스타를 많이 먹으면 살쪄”라는 결론이 그럴 듯 하지만, 몸무게로 군집하여 보니 그 그렇다고 할 수 없지요? 이렇듯이 통계를 내는데 중요한 항목을 빠뜨리고 결론을 내버리면 결론이 반대로 나와버리는 경우를 심슨의 역설이라고 합니다.
5. 기타 Spurious Correlation
동양에서는 옷깃만 스쳐도 인연이다. 혹은, 네가 그렇게 망한 것은 네 업보다. 라는 말이 있지요. 이런 말들이 정말 진실일까요? 과학적으로는 증명되지 않습니다.
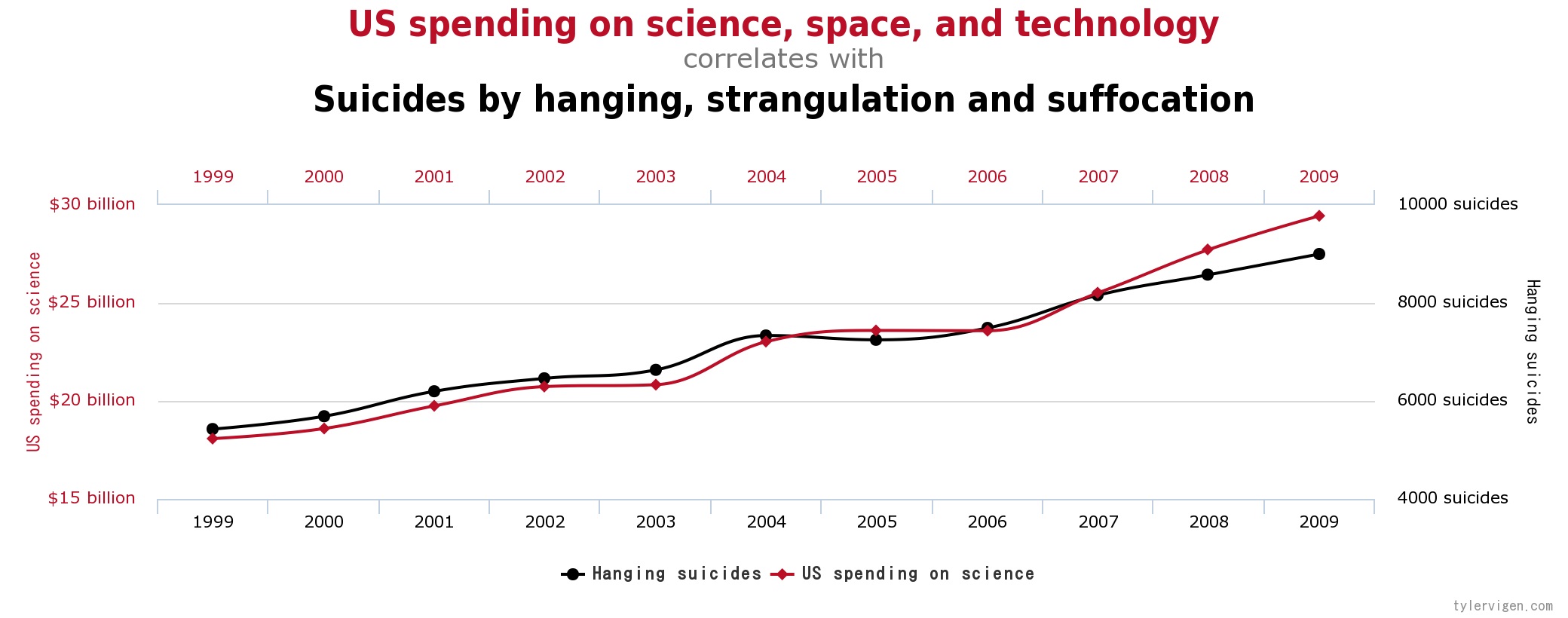
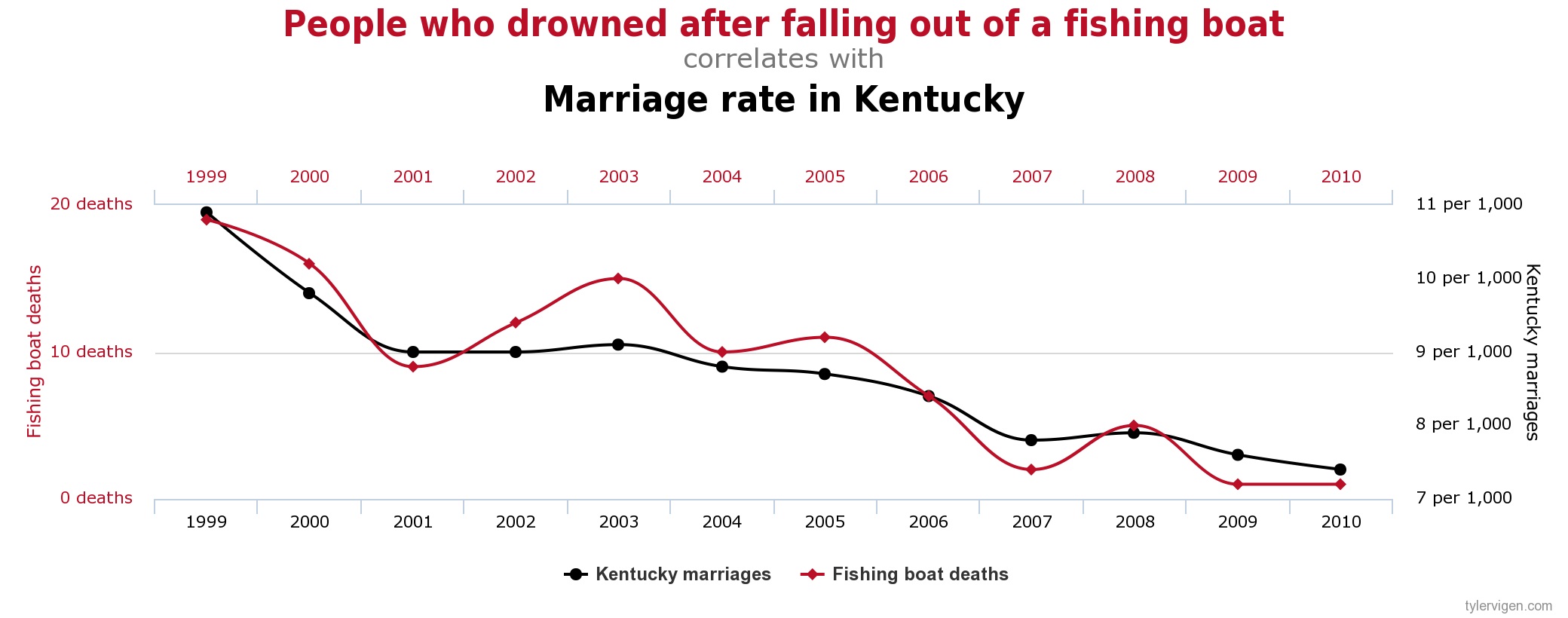
다음 그래프는 미국의 과학기술투자와 자살한 사람들의 숫자에 대한 그래프입니다. 그래프 자체만 보면 둘이 상당한 상관관계를 가지면서 움직이는 듯 하게 보입니다. 그렇지만 상식적으로 미국이 과학기술투자를 많이 하면 자살하는 사람이 많아질까요?
서양문명은 이러한 관련이 있어 보이지만 합리적인 인과관계를 찾을 수 없는 경우를 Spurious Correlation이라고 부릅니다. 쉬운 말로 우연의 일치(Coincidence)라고 합니다.
6. 결론
사실 이 글에서 특별한 결론은 없습니다. 통계에 대해서 상식적으로 알아두어야 하고, 어디에서 오류가 생길 수 있는 부분에 대해서 복습을 한 셈입니다. 어떠한 것은 인과관계가 확실하지 않은 것도 있습니다. 예를 들어 몸이 안좋으면 기분이 나빠집니다. 그런데 기분이 나빠지면 몸이 안좋아집니다.
서양의 통계학은 "물질과 사리에 정통해 있다."는 말씀과 같이 상당히 많이 발달했습니다. 또한 통계를 조작하는 법도 많이 발달했습니다. 여성부 예산 27조는 어디로 가는지...
※ 혁명은 증산상제님의 갑옷을 입고 행하는 성사재인이다
※ 밀알가입은 hmwiwon@gmail.com (개인신상은 철저히 보호됩니다)
※ 군자금계좌: 농협 356-0719-4623-83안정주
※ 통합경전계좌 : 국민은행 901-6767-9263노영균sjm5505@hanmail.net
※ 투자금 계좌: 하나은행 654-910335-99107 안정주